monocle是一个基于R的生物信息分析包 . 应用于单细胞转录组测序. 其中最厉害的是拟时分析, 研究细胞的分化轨迹, 让我们看一看拟时分析的原理.
Monocle不简单
monocle是一个基于R的生物信息分析包 . 应用于单细胞转录组测序. 之前的文章中已经整理过关于单细胞测序的一些基础知识. 需要的同学可以跳转《单细胞测序学习比较-原理》.
虽然单细胞目前分析的内容还是相对单一, 但是就是"相对单一"的分析内容里, 就有灰常复杂的细节值得我们去深究😫. 首先就是:
- 1️⃣
Tsne和UMAP分群原理 - 2️⃣ monocle构建伪时间发育轨迹的原理
这两者算是目前我了解里面, 最难的部分了 😰. 所以需要额外的找一找资料补充一下头脑. 这次主要针对的是monocle中拟时分析做一番学习✏️ 📚.
资料主要来自参考文献中第一篇, 发表在**《Natrue method》**上的文献[1], 也是Trapnell实验室的monocle拟时分析的主要原理介绍.
文章成果: 开发Monocle算法,利用无监督算法,预测转录组动态的在时间上的发育轨迹.
研究内容: 作用利用在多个时间点收集的人类成肌细胞💪的单细胞RNA-Seq数据。用Monocle揭示了关键调节因子表达的时间维度上的变化,展示了基因调控的连续波动📈 📉, 以及预测了将来的调节因子的表达.
最后作者进行分子实验验证了一些预测的结果。
拟时分析
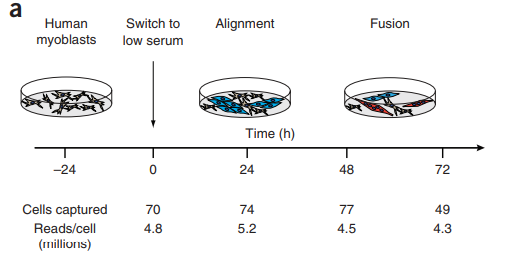
实验设计和取样
成肌细胞在高血清培养基中培养。在转换为低血清培养基后,将细胞解离后, 并以24h间隔取样。然后,总共四个时间点, 每个时间点捕获49到77个细胞. 使用Fluidigm C1微流体系统测序(真有钱, 小声BB)💰💰💰。分离来自每个细胞的RNA, 并针对每个细胞构建mRNA-Seq文库,然后每个文库约4M的read,意味着每个细胞都能得到完整基因表达谱.
算了一下, 每个细胞4M的reads, 也就意味着0.6G的数据量/每个细胞.
任性啊, 大佬
开发monocle
然后大佬就开发monocle了💯(真任性 小声BB), Monocle按照细胞的转录本丰度信息进行信息排序, 模拟细胞的分化轨迹. Monocle对比之前的算法, 其优点在于不依赖先验知识(前人证明的分化轨迹的biomaker). 而是采用无监督的方法,最大化连续模拟细胞之间的转录相似性。
原理(详细的看附录)
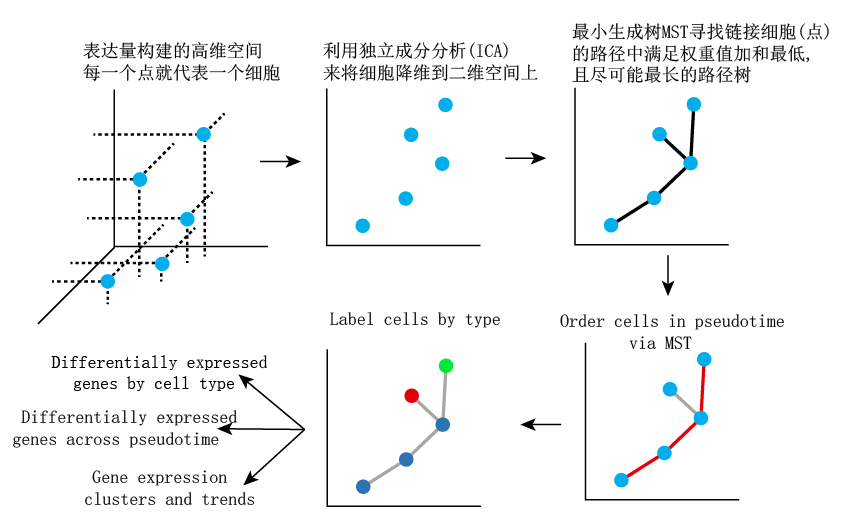
首先,该算法根据细胞的表达谱信息, 将细胞表示为高纬度欧氏距离空间中的一个点 (每个基因具有一个维度)。
这部分还是比较好理解, 就是我们常说的普通转录组也有这样的高纬欧式空点坐标, PCA的算法就是在高纬空间中, 重新建立坐标系, 而所有点的投影距离最短的坐标轴就是PC1, 其次是PC2,,,,巴拉巴拉的.
PCA是要懂得,要不然怎么学习组学
其次,它使用独立成分分析来降低该空间的维数。维度降低将细胞数据从高维空间转换为低维空间,保留细胞群之间的基本关系,但更容易可视化和解释.
想想你的PCA, tsen, UAMP, 这个概念还是很好理解的.
问题是这个ICA是什么😱? 看附录
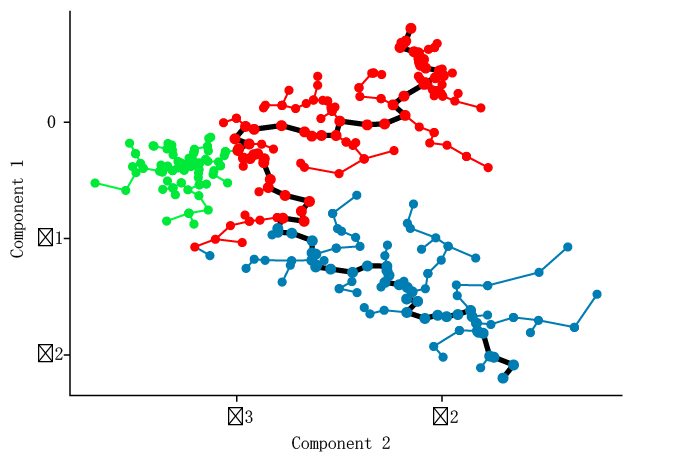
这样将细胞展现在ICA分析后的低维空间😨(就是平面二维空间)发散下思维, 能不能换一种图形展现拟时分析,答案就在这一句话中 . 得到细胞的二维空间的坐标后, 利用最小生成树(MST)进行分析.
算法找到MST分析结果中, 最长路径. 然后monocle再稍微美化一下. 总之. 这个最长的路径就是单细胞的主要分化轨迹. 随着细胞沿着分化轨迹前进,细胞偶尔也可以沿着两个或更多个分开的路径发展😖。
所以在Monocle找到最长的MST路径(主分化途径)后. 它会检查不沿此路径的细胞. 然后再对这些细胞进行MST的单独分析. 再找到一个轨迹。
最后monocle命令这些子轨迹连接到主轨迹,在这一系列的分析后, 因此,Monocle通过细胞的基因表达谱,重建细胞分化过程. 这个过程中最重要的是,Monocle是无需监测的,并且不需要任何前人研究的先验知识(例如, 决定细胞命运的特定biomaker等认知),因此适用于研究各种动态生物过程💯。
分析步骤
如图[[1]](# ref01)
附
算法
ICA独立成分分析
我的天啊, 你竟然对这个感兴趣, 好变态啊😎. 我劝你你还是跳过这一部分💊💊💊, 因为这部分了解与不了解, 在工作和生活中用处都不是很大👽.
如果有兴趣, 那我们就一起看看这个ICA分析👴👴👴.
独立成分分析的最重要的假设就是信号源统计独立。独立成分分析的经典问题是“鸡尾酒会问题”。该问题描述的是给定混合信号,如何分离出鸡尾酒会中同时说话的每个人的独立信号[3]。
独立成分分析的目标就是从混合个体信号中, 区分来自个体的信号. 这个概念可是和PCA完全不同的, PCA专注的是找到具有代表意义的主成分. 而ICA关注是混合信号中的个体信号[2]. 如图:
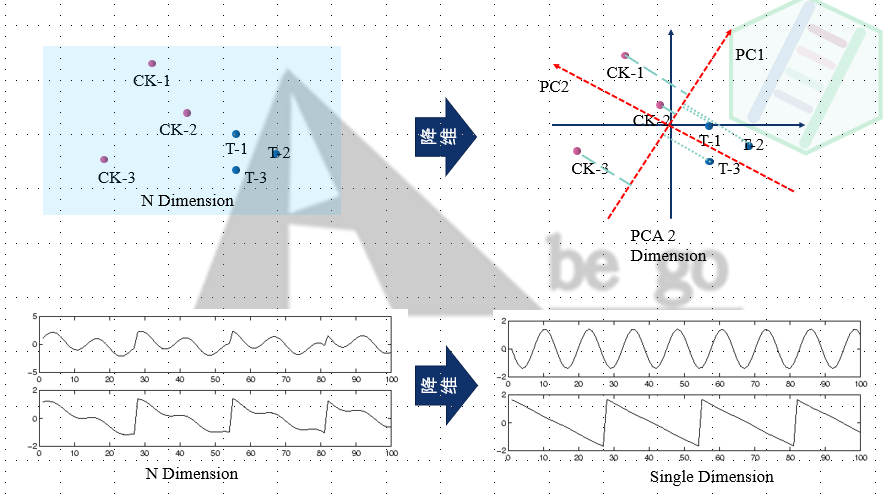
如果还想继续学习, 花钱买书吧[4], 这本书还是有中文译版的:trollface:

MST最小生成树
既然你都已经看完了ICA, 那就接着看下一个概念最小生成树Minimum spanning tree😈, MST算法应用非常广泛. 其主要概念就是:
在有权无向网络图中, 寻找链接所有或部分点的最小权重加和的路径
有没有感觉被我说的更复杂了
有权无向网络图:octocat:, 最直接的了解就是WGCNA的网络. 这点可以看《图论好难, Network理论和WGCNA分析》, 简单来讲就是网络图中点与点之间没有方向, 但是两点之间的关系(连线)是有权重值的. 而最小生成树就是需要在一个网络中尽可能地将更多的点链接起来, 同时找到所有边权重加和最小的链接方式[5].
举个例子, 村里通网, 其中有40户人家准备安装网线, 电信公司怎么铺网线, 才能保证所有40个 用户都能通上网, 同时网线铺的最短.
例子中, 网线的长短意味着成本的不同, 这就是这个例子中的权重💰💰💰.
题外话
最终monocle这篇文章[1]是发在了NB上, 确实是🐮🍺. 但是我们还是要注意到, 作者这边文章是2014年发的,那时候连drop-seq都没有, 更何况商业化推广的10x genomics呢, 所以当时作者做的是smart-seq, 一共收集了大约300个细胞. 每个细胞0.6G的测序量
❗重点: 拟时分析不是高通量单细胞测序专有的, 更不是10x genomics所专有的. 所以这个概念一定要了解. 另外细胞太少, 用monocle做拟时分析是不是也太寒碜了🙉. 不过值得一试😏. 我之前就遇到老师想做32个的单细胞, 但是也想做拟时分析. 我当时回答是: 能做, 但是效果不好😵. 现在想想还是蛮明智的☺️.
参考文献:
[1] Trapnell, Cole, Davide Cacchiarelli, Jonna Grimsby, Prapti Pokharel, Shuqiang Li, Michael Morse, Niall J Lennon, Kenneth J Livak, Tarjei S Mikkelsen和John L Rinn. 《The Dynamics and Regulators of Cell Fate Decisions Are Revealed by Pseudotemporal Ordering of Single Cells》. *Nature Biotechnology* 32, 期 4 (2014年4月): 381–86. [2] [ 《独立成分检验》](http://cis.legacy.ics.tkk.fi/aapo/papers/IJCNN99_tutorialweb/node1.html).
[3] [《独立成分分析》](https://zh.wikipedia.org/w/index.php?title=%E7%8B%AC%E7%AB%8B%E6%88%90%E5%88%86%E5%88%86%E6%9E%90&oldid=47787653](https://zh.wikipedia.org/w/index.php?title=独立成分分析&oldid=47787653))维基百科,自由的百科全书, 2018年1月11日.
[4] [《独立成分分析 - china-pub网上书店》](http://product.china-pub.com/190764#xy) 2019年6月17日.
[5] [《最小生成树》. 维基百科,自由的百科全书, 2019年3月25日](https://zh.wikipedia.org/w/index.php?title=最小生成树&oldid=53729411).